



4月24日,国产大模型DeepSeek(深度求索)发布DeepSeek-V4预览版并全面开源,瞬间引爆AI圈。
这款新模型不仅把超长上下文(约75万字)做成标配,推理成本还大幅下降。而它的每一次对话、每一次复杂任务执行,背后都在消耗同一个单位——Token(词元)。
很多人只听过Token,但可能不懂它到底是什么?扣不扣费?背后是谁在运营?和各类AI大模型有什么关联?
AIToken到底是什么?
国家数据局局长刘烈宏,在中国发展高层论坛2026年年会上表示,Token“词元”不仅是智能时代的价值锚点,更是连接技术供给与商业需求的“结算单位”,为商业模式的落地提供了可量化的可能。
这给出了Token的中文翻译:“词元”。
直白来讲,AI其实听不懂我们日常说的话,也看不懂完整的文案、报表。
人类输入的文字、指令,还有AI输出的回答,都会被大模型自动拆分成一个个统一规格、方便识别的最小基础碎片。
这些碎片,就是Token。
可以打个很生活化的比方:Token就相当于AI世界里的电费+流量+汽油三合一。
汽车要烧油、手机要用流量、家电要耗电,同理,大模型只要开始工作、响应你的指令,全程都在实实在在消耗Token。
不管是你输入的提问,还是AI给出的回复,每一段文字都会按Token来统计、计费。
不同大模型的分词规则、编码方式、输出习惯不同,同样一段中文,不同大模型对Token的消耗量也不相同。可以近似地认为一个汉字就是一个Token。
Token的演进趋势:从“对话消耗”到“任务消耗”,需求爆发
行业发展到现在,Token的消耗模式已经发生了本质变化。
早期是“对话消耗”,单次聊天只用掉很少的Token。
现在已经转向“任务消耗”——比如AI智能体执行多步骤复杂任务时,单任务Token消耗能从几千级直接冲到百万级。
需求爆发式增长,也让Token成为AI行业新一轮增长的重要驱动力。
根据国家数据局统计:
2024年初,我国日均词元(Token)调用量约1000亿;
2025年底,跃升至100万亿;
2026年3月,已突破140万亿。
两年时间增长超千倍。
Token调用量越高,通常意味着模型使用越频繁、市场需求越旺盛。
据OpenRouter最新数据,在3月30日-4月5日这一周:
全球Token调用量前六名,全部是中国AI大模型,其中千问模型(Qwen3.6 Plus)位居第一,周调用量达4.6万亿。
中国AI大模型的Token周调用量已连续五周增长,并且连续五周超过美国。(截至2026年4月5日)
中国AI正在全球竞争中,从跟跑加速转向领跑。
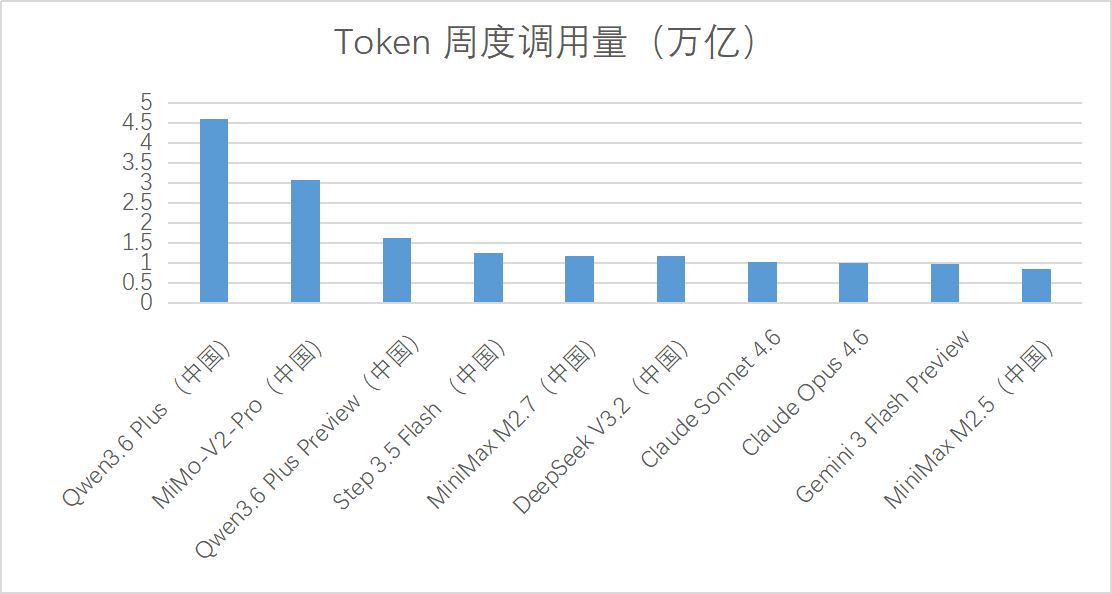
数据来源:OpenRouter平台,2026年3月30日-4月5日周度统计数据。
注意,OpenRouter是全球主流的大模型聚合平台,其数据主要反映开发者、中小企业与个人用户的真实API调用与Token消耗需求,不反映面向普通用户的App端日活或注册量。该数据仅展现OpenRouter单一平台,具有一定参考价值,但不能直接等同于整体市场的真实表现。
对投资者而言,Token数据意味着什么?
Token看似是AI后台的技术计量单位,实则是观察行业景气度的重要量化指标。
调用量的持续增长、结构从简单对话转向复杂任务、中国模型在全球榜单上的持续领先,都在直观反映产业落地速度、用户真实需求强度以及技术竞争力的变化。
这些高频、真实的使用数据,能为我们理解AI产业发展阶段、判断行业趋势提供更客观、更贴近实际的参考视角。



